本篇文章作者 ius,本文属 i 春秋原创奖励计划,未经许可禁止转载
原文地址:https://bbs.ichunqiu.com/thread-63784-1-1.html
微博反爬机制逆向分析
前言
相信每个接触爬虫的人,肯定会对微博进行一点点的骚操作。但是我们在对微博进行请求的时候,微博是会对cookie校验的,而我们在模拟操作的时候,是直接把浏览器的cookie进行copy,虽然我没有测试过这个cookie的有效期,但我觉得这样只适合日常测试,教学等。不能实现一劳永逸。
当我们没有携带cookie进行微博的访问时,会出现Sina Visitor System字样的标题,如果我们是正常的浏览器访问的话,这个空白页面会一闪而逝,然后跳转到微博界面。所以我们可以确定,这个页面就是微博的反爬机制,我们的研究也就从此处开始。
正文
测试链接:https://s.weibo.com/weibo?q=%E8%9C%98%E8%9B%9B%E4%BE%A0
打开一个无痕界面,在F12中打开 停用JavaScript,因为空白界面一闪而逝,我们要先停掉跳转,方便分析。

访问链接,我们看到了这个反爬页面的全貌,此处空白是空白页的颜色,,,

我们对此处断点,断点后再刚才的地方关掉停用JavaScript,刷新界面,发现断点成功

我们的目的是找到生成cookie的位置,知道目的之后,我们开始逐步分析
走完html发现进入到了这个js文件内,微博人挺好的,还把每块代码的作用给注释好了


虽然我很想把每一步的调试都发出来,但是实际上大部分的操作都没有记录的意义。。。所以我就把关键的部分写出来,节省大家的时间。
当我们断点跟到此处的时候,我们发现了设置cookie的代码
(其实不单步调试也可以,直接搜cookie也能搜出来。但是在我们逆向之前,我们并不清楚这类代码有没有被混淆。。。所以在最开始我并没有搜索关键字。。)


我们向上找堆栈,看看cookie是如何生成的。
嘿,您猜怎么着!
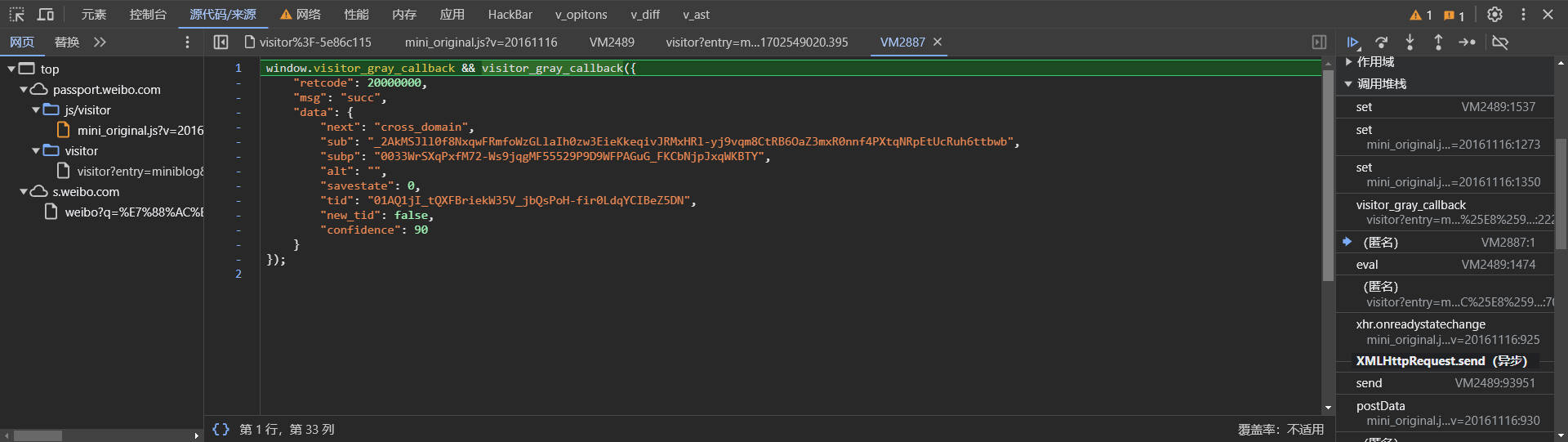
看到此处的我大吃一惊,因为这并不是js代码。。反而是一个请求返回内容
然后继续向上看,跟到了刚才的空白页中。
好好好好,你家cookie不从本地生成从网络请求是吧!
此处省略无数个点


既然知道是从网络请求的cookie了,我们就打开网络面板,揭开他神秘的面纱:)

这样看太费劲了,我们copy到postman里分析,同时也是为了方便调试

ctrl+o直接把curl甩进去,接着我们请求一下,可以看到请求成功的cookie正安详的躺着。
POST的内容也是固定值,看样子没有什么要分析的

我们点击右侧边栏的<> 然后转换成python语言,放到ide里好好拷打一番
ok,不负众望,我们也是请求成功

然后我们使用正则,将cookie中的SUB、SUBP、tid提取出来,然后我们再次运行

没有问题,我们包装成函数,方便调用,顺便改个文件名方便导入


下面进行测试看看,先导进来看看能不能用

请求正常,我们用刚才的测试链接进行访问试试
访问失败了???!!!!

在这里我又进行了无数次的调试,抓包。结果最终发现。。。


是这里的cookie名称写错了,应该大写为SUB、SUBP。Tips:tid在后来测试中发现没用使用,然后我就删掉了
修改完之后,我们再来测试一下,不出意外的话,这次是真没出意外
请求成功了!

至此,我们的微博反爬机制成功绕过!
此处应该有掌声。
经过我多次请求发现,这个地方的cookie是跟IP地址有关的,只有更换IP后才会刷新cookie。当然,如果当前IP的访客cookie过期的话,是会自动更新的。
后记
写完代码之后,想起来之前写的一个微博扫码登陆程序,最开始的时候是可以用的,后来再次请求的时候会出现Sina Visitor System,当时技术有限,不知道怎么解决。这次既然解决了,把cookie带上看看能不能成功运行
不出意外的话,这次肯定不会出意外了。
代码成功运行,获取登录cookie成功!

——圆了高中时期,在手机上逆向微博生成短链接的梦。

你好